最开始接触到环形缓冲区(ring buffer)还是在上《数据结构》这门课时,当时对这种数据结构没有多深的认识,这是因为对其在项目中实际应用缺少足够的认识。最近,由于在项目中遇到了类似任务间通信的需求,所以再来研究研究这位“老朋友”。
概述
环形缓冲区是一种抽象的数据结构,顾名思义,其通常来充当数据的 “缓冲”。例如,在网卡接收数据时,CPU 并不一定会去及时的读取它,这时,缓冲区就派上用场了。缓冲区可以理解为一片内存空间,网卡中断服务程序会在收到网卡中断时,及时的从网卡将数据读取到缓冲区中,之后,这些数据就等待被进程读取了。
而使用环形缓冲区这种抽象,是因为其如下特点:
- 当一个数据元素被读取出后,其余数据元素不需要移动其存储位置;
- 缓冲区的容量(长度)一般固定,可以用一个静态数组来充当缓冲区,无需重复申请内存;
简单实现
由于计算机内存是线性地址空间,因此 环形缓冲区(ring buffer) 需要特别的算法设计才可以从逻辑上实现。
简单的例子
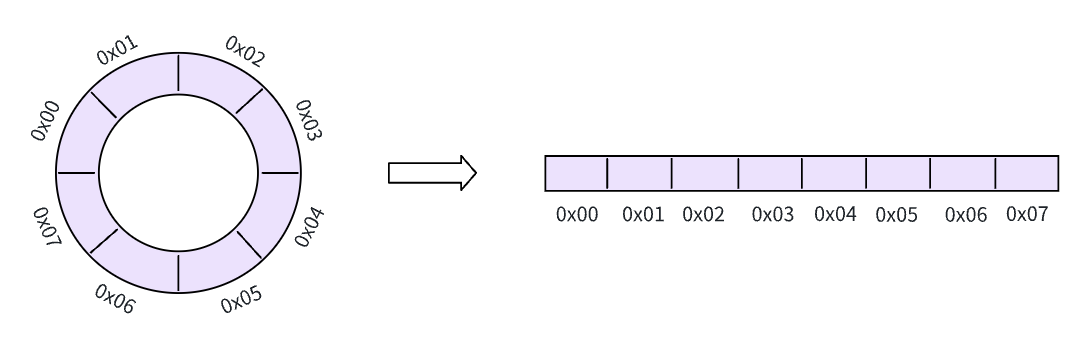
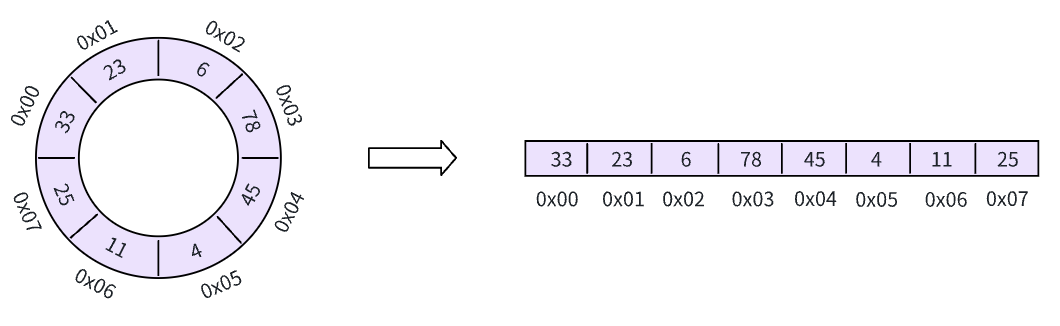
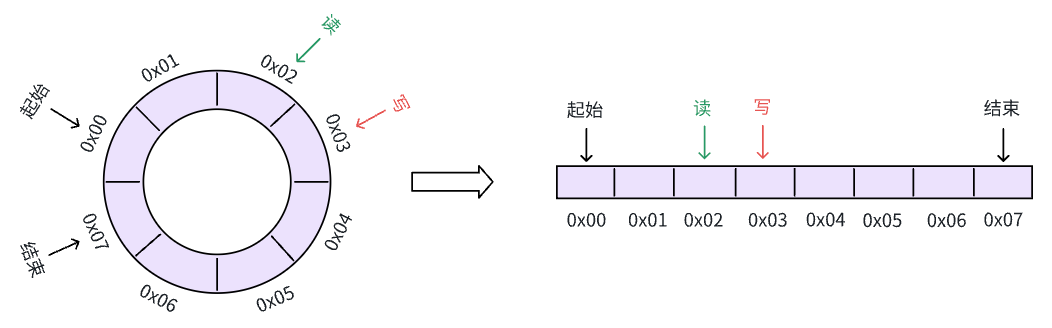
如下是一个空间大小为 8 的环形缓冲区,左边是其抽象数据结构,后面使其具体在计算机上的实现
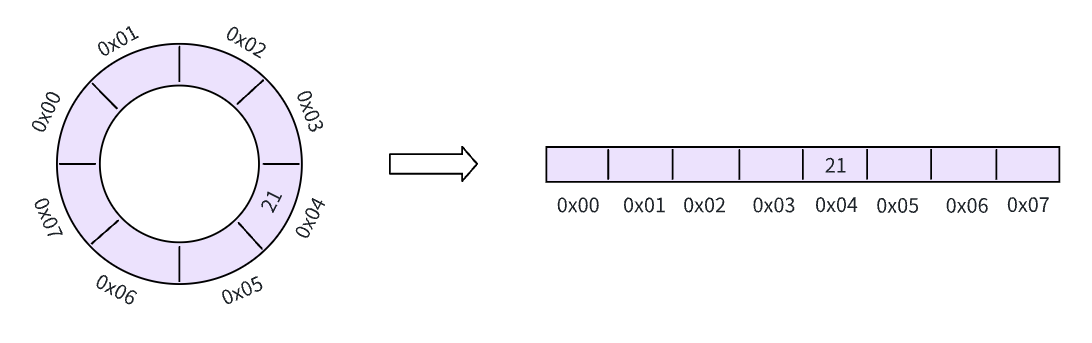
下面我们向缓冲区内写入一个数据,可以看到数据被写入到了 0x04 这个地址
我们继续向缓冲区内写数据,下一个可以写入的位置是 0x05 这个地址,这一次我们多写几个数据,直到 0x07
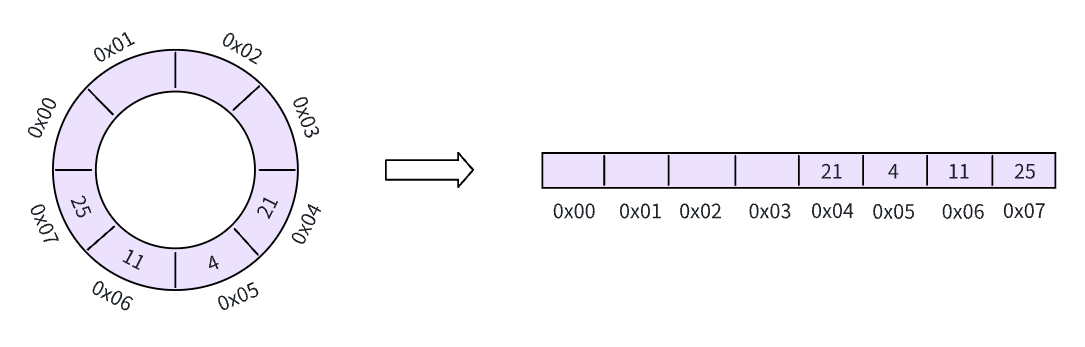
这时,我们发现右边已经到达了缓冲区末尾,如果还想继续写入数据该怎么办呢?
很明显,从左边的抽象数据结构可以看出,末尾的下个可用位置就是开头 0x00 这个地址,我们继续插入
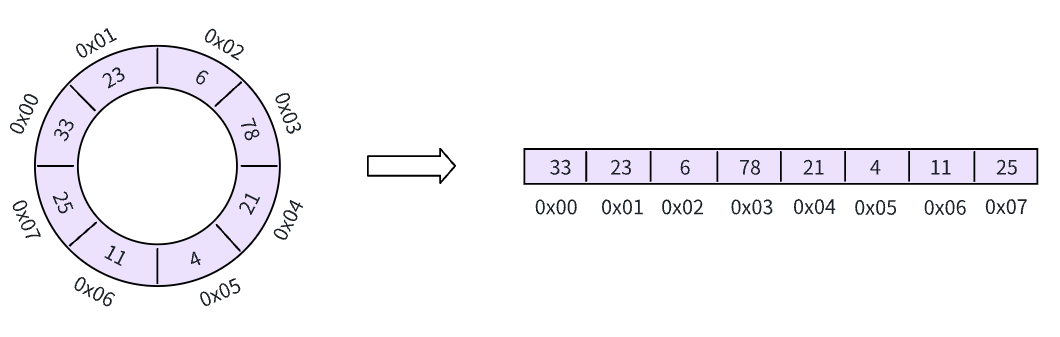
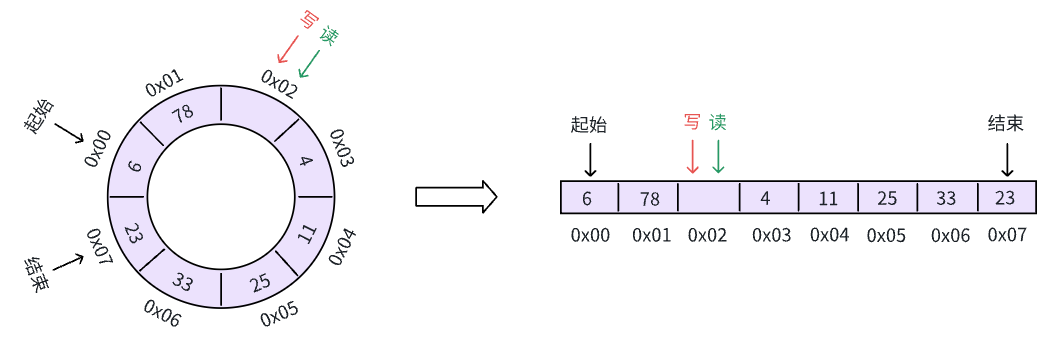
这一次,我们直接把缓冲区写满了!!这时候该怎么办呢?一般有两种方案:
- 覆盖掉老数据,假设我们继续向缓冲区写入一个数据:
可以看到,我们最先写入的 21 这个数据被45 覆盖了
- 第二种也比较简单,直接告诉想要写入的进程:”我已经满了,不能再写了“,返回一个错误信息即可
试着实现
上面的大致流程我们已经了解了,那具体的细节还有什么要注意的呢?
一般的,对一个环形缓冲区进行读写操作,最少需要4个信息:
- 在内存中的实际开始位置(例如:一片内存的头指针,数组的第一个元素指针);
- 在内存中的实际结束位置(也可以是缓冲区实际空间大小,结合开始位置,可以算出结束位置);
- 在缓冲区中进行写操作时的写索引值;
- 在缓冲区中进行读操作时的读索引值。
这一次,带着这些细节,再看一次缓冲区的读写操作,初始状态如下所示:
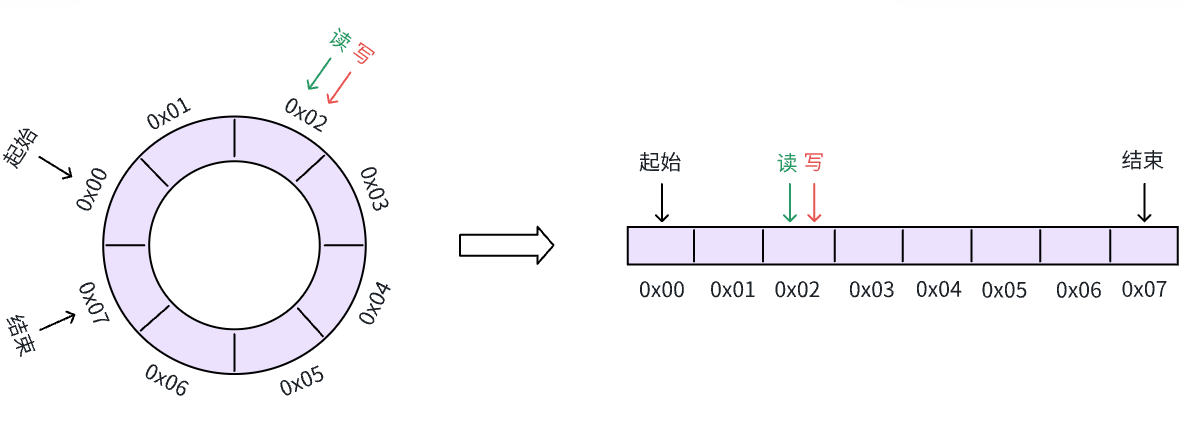
向缓冲区写入一个数据:
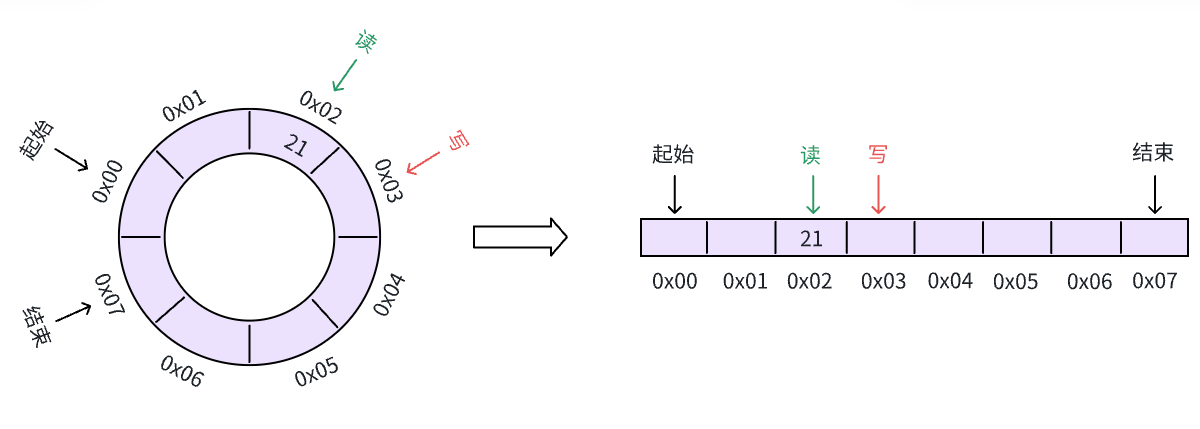
继续写入数据,这次直接写到了缓冲区结束的位置,此时,按照环形的逻辑,我们应该将写指针放到下一个写入的位置,也就是缓冲区开头:
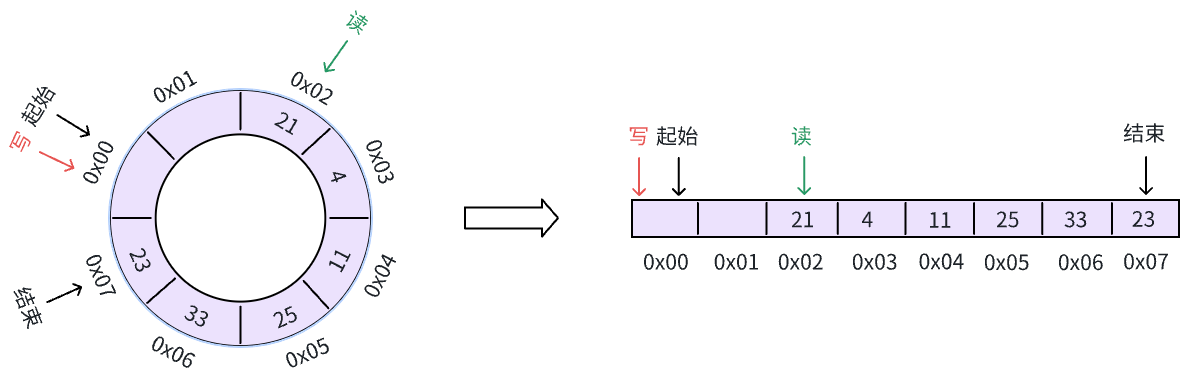
接着,我们试着读取一个数据,可以看到,读指针向后移动的一位:
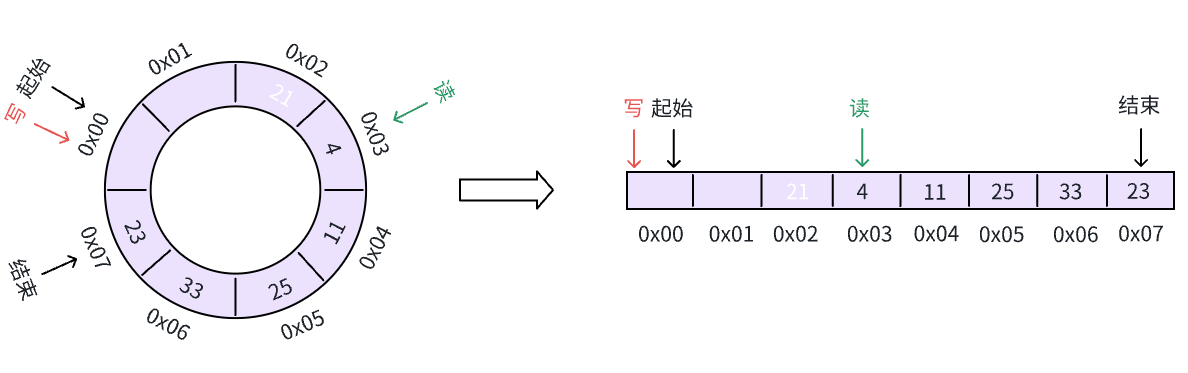
最后,我们把缓冲区填满,写、读指针再次相遇:
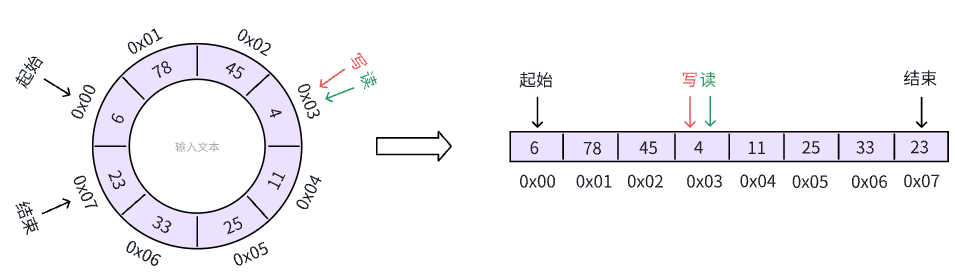
尴尬的读写指针
在我们上面的描述中,初始时,读写指针都指向了 0x02 地址的数据,此时,缓冲区是空的,什么数据都没有。在我们描述的最后,读写指针都指向了 0x03 地址的数据,此时,缓冲区是满的,无法在插入新数据(除非覆盖)。
有什么不对劲的地方吗?
是的,我们的缓冲区在空和满 的时候,四个指针的状态是一致的!这显然是没法满足需求的,因为我们没法给想要写入数据的进程提供正确的信息,即现在缓冲区是不是满了。
如何解决这个问题呢?有一个简单的方法,原则就是让读写指针在空和满时,保持一个不一样的状态
一个能用的版本
上面我们提到,只要打破”读写指针在缓冲区空和满时指向相同的位置”这一状态即可
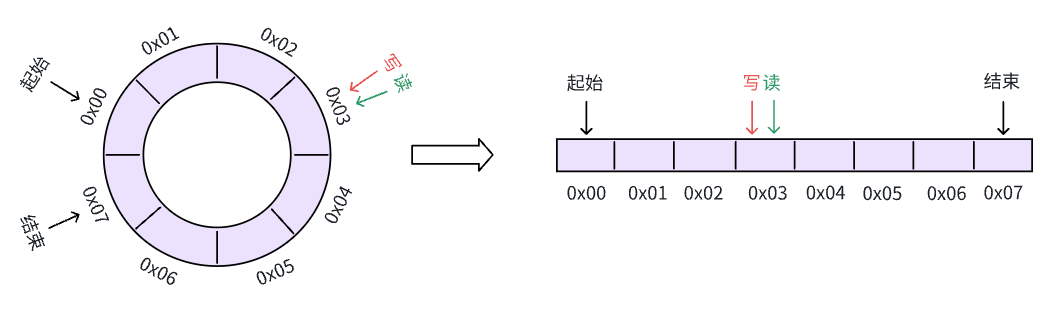
1、空的时候指向同一位置,满的时候差一位
空:
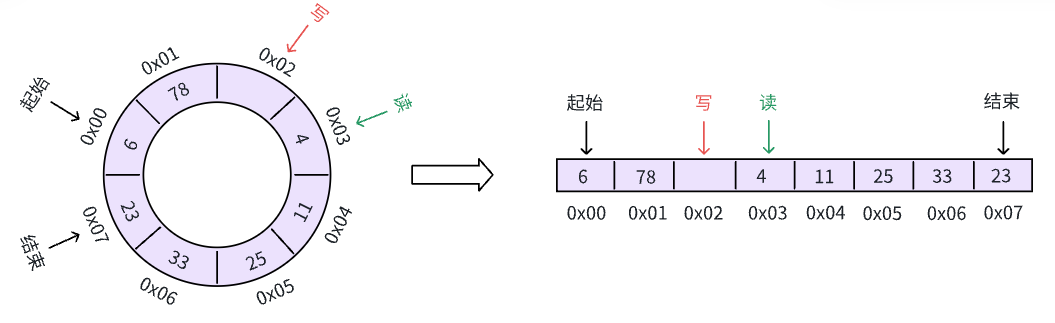
满:
2、空的时候差一位,满的时候指向同一位置
空:
满:
C语言实现
抽象出我们需要的 4 个要素:起始地址,读指针,写指针,结束地址
这里使用缓存区的长度,代指结束地址,使用数组索引代指读指针
1 | typedef struct { |
- 读取之前需要判断缓冲区是否为空 (这里我们使用上面提到的第一种方式)
1 | int rbuf_is_empty(ring_buffer_t *buf) |
- 读取一个数据:先根据读指针的位置写入数据,然后再移动读指针的位置,移动时要判断是否到了缓冲区末尾
1 | int rbuf_read_char(ring_buffer_t *buf, char *ch) |
- 写入之前需要判断缓冲区是否已满:
1 | int rbuf_is_full(ring_buffer_t *buf) |
- 写入一个数据:先根据写指针的位置写入数据,然后再移动写指针的位置,移动时要判断是否到了缓冲区末尾
1 | int rbuf_write_char(ring_buffer_t *buf, char ch) |
- 获取缓冲区有效数据大小 :
1 | int rbuf_size(ring_buffer_t *buf) |
稍微解释下缓冲区数据大小的计算:
当
write指针大于read指针时,加上的buf.len会在取余时被忽略掉,结果就等于write - read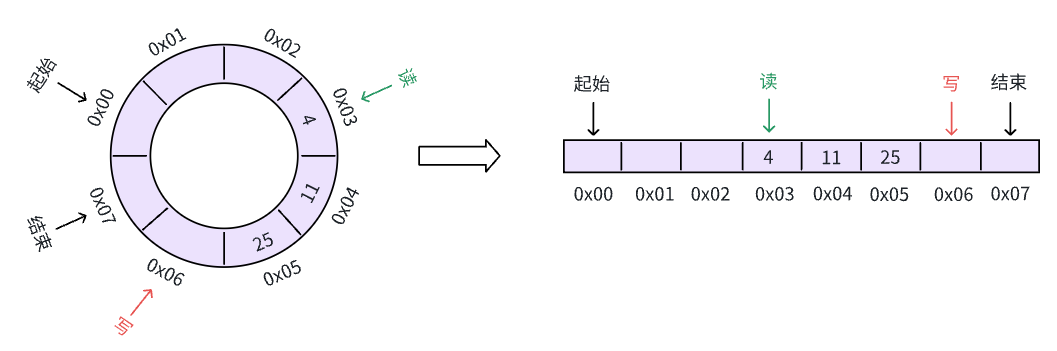
当
write指针小于read指针时,加上的buf.len相当于将write指针拓展到了2 * buf.len的范围中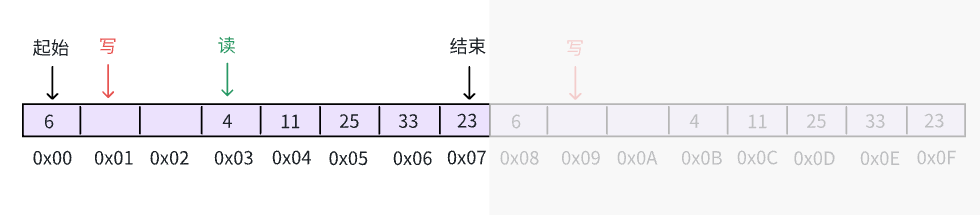
再进一步
我们上述的简单实现中,为了避免缓冲区空和满时状态一致,舍弃了一个存储空间,打破了上述一致状态。当然,一单位存储空间的浪费还不足以让我们摒弃上面的实现方法,更重要的是,上面的方法中,充斥着大量的 % 求余运算。求余运算的操作比较耗时,在对性能要求较高的场景下,我们的实现还有优化的空间。
重新审视 ‘%’ 取余操作
在汇编指令的实现中,取余操作往往意味着需要进行除法运算,这涉及到使用的除法指令,如 x86 下的 IDIV。
计算机支持的运算中,算数运算耗费的时间远远大于位运算的时间,其中除法更甚,往往能到达几十个时钟周期,而位运算通常只需要一个时钟周期,所以,使用位运算替代算数运算,能极大提高程序性能。
取余运算也是如此,当模 为2的a次幂时(0b10000…)可以使用位运算,取代取模运算,提高性能
1 | m % n == m & (n - 1), 其中 n 满足 n & (n - 1) == 0, 即 n == 2^a |
因此,第一个可以优化的地方出现了,保证缓冲区的长度等于2的幂,使用位运算取代取模运算
镜像指位法
在简单的实现版本中,我们把读写指针放在了 [0, n - 1] 这个区间内,使得缓冲区满和空两种时,读写指针的状态相同,指向了同一个位置,除了通过舍弃一位来避免这种情况外,还有什么更好的方法吗?
考虑这样的办法,假设缓冲区大小仍为 n,但是将读写指针的范围扩大到 [0, 2n - 1] ,其中 [0, n - 1] 的范围为真实的缓冲区区间,[n, 2n - 1] 作为镜像区间,用来辅助判断缓冲区是否为空。当读写指针落在镜像区间时,其对应到真实区间的索引为 write & (n - 1) 或 read & (n - 1) 。
缓冲区为空时,write == read 或者说, write & (n - 1) == read & (n - 1) 并且二者都落在真实区间:
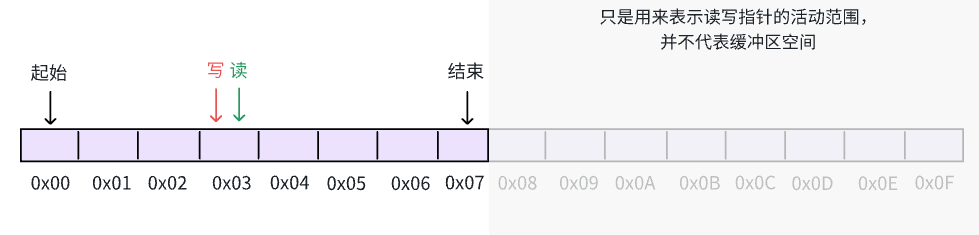
当缓冲区已满时,此时的写指针真正的超越了缓冲区容量大小,真实指向位置通过 write & (n - 1) 计算得出。在这种情况下, write & (n - 1) == read & (n - 1) 并且一个在真实区间,一个在镜像区间:
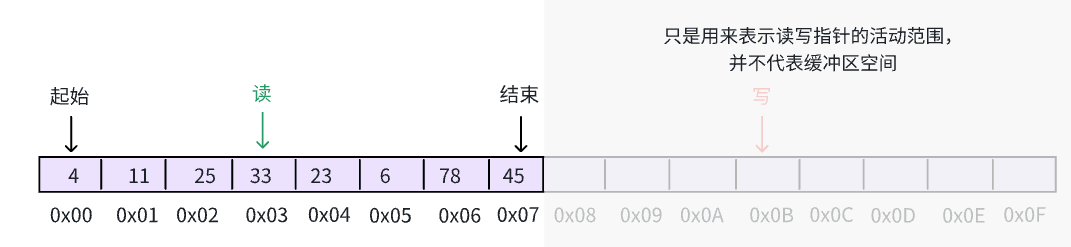
紧接着,将数据从缓冲区读出,直到缓冲区为空,在这种情况下, write & (n - 1) == read & (n - 1) 并且二者都落在镜像区间:
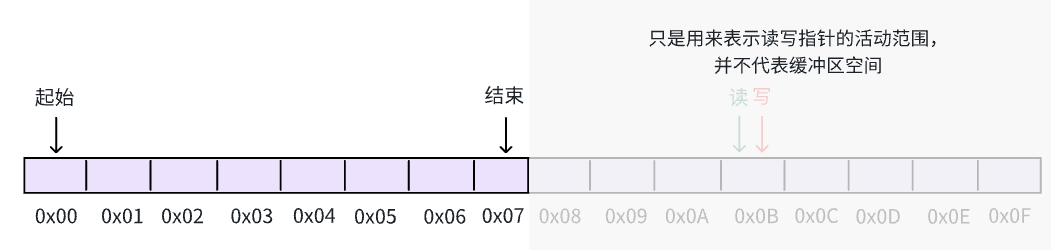
此时,继续缓冲区写入数据,直到缓冲区再次被填满, write & (n - 1) == read & (n - 1) 并且一个在真实区间,一个在镜像区间:
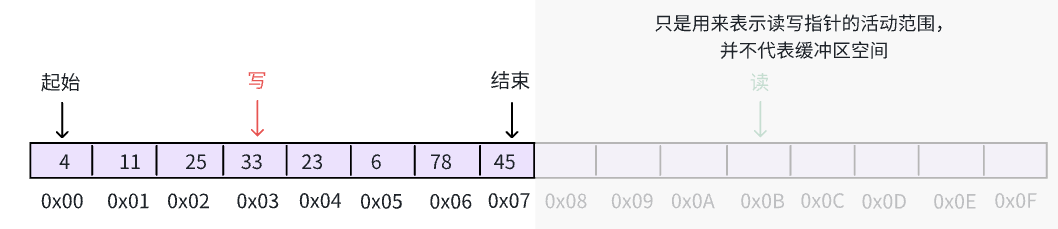
最后,我们将所有的数据读出,缓冲区再次被清空,此时, write & (n - 1) == read & (n - 1) 并且二者都落在真实区间:
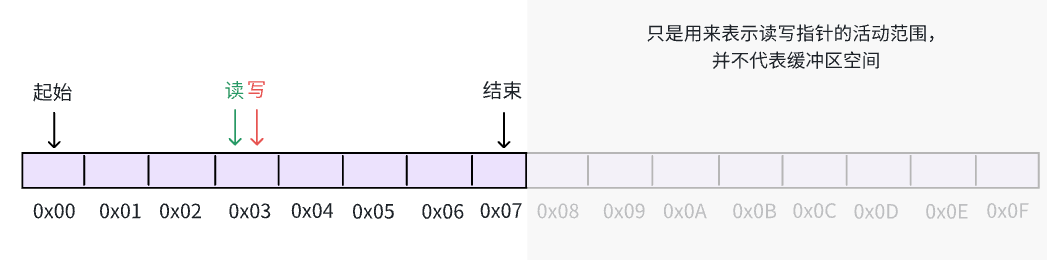
如何确定缓冲区何时为空何时已满呢?从上面的描述中已经可以清晰地看出:
write & (n - 1) == read & (n - 1)并且 二者在同一区间时,缓冲区为空write & (n - 1) == read & (n - 1)并且 二者不在同一区间时,缓冲区为空
很自然的,我们可以各使用一个比特位,代表读指针和写指针所在的区间,如 0代表在真实区间,1代表在镜像区间。
先进先出队列
现在,在镜像指位法的基础上,我们进一步拓展,假设读写指针没有增长上限会是怎样的情形呢?这时,我们需要区分出读指针,写指针和读索引,写索引的区别,其中:
读索引 = 读指针 & (n - 1)
写索引 = 写指针 & (n - 1)
当读指针和写指针相同时,缓冲区为空,二者相差 n 时缓冲区满。这只是理想情况下的例子,现实中并不存在。但是,我们可以通过巧妙的计算,来实现这种模型。我们使用 无符号的整型来代表读写指针,其范围是 [0 - 2^32 - 1],我们记 MAX = 2^32 - 1。
读写均为溢出 :当读写指针均未溢出时,一切正如我们上面描述的那样正常,假设缓冲区大小
size,写指针w, 读指针r,则剩余空间大小为:size - (w - r)写指针溢出,读指针未溢出 :这种情况下,由于是无符号整型,写指针溢出后会回绕为 0,我们举个例子,看看如何计算可用空间的大小:
假设缓冲区大小
size= 8,写指针w= 2, 读指针r= MAX - 1,此时剩余空间大小为8 - (2 - MAX + 1)即MAX + 5,由于无符号整型的溢出原则,MAX + 5溢出为4,这正是我们的剩余空间大小!!!此时,已经写入缓冲区的元素个数是
2 - MAX + 1即3 - MAX=3 + MAX + 1 - MAX= 4 ,这也正是我们已写入数据的个数!!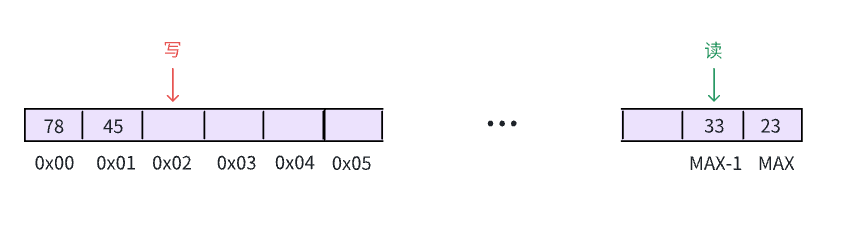
读指针溢出,写指针未溢出 :这种情况不存在,因为读指针永远不会超过写指针
上面,我们已经讨论了所有可能出现的情况,发现剩余空间大小都可以用 size - (w - r) 表示!已经写入的元素都可以用 w - r 表示!感谢无符号整型的溢出回绕特性,让我们可以轻松的实现一个理想的缓冲区。
理想缓冲区实现
先来看结构:
1 | struct kfifo { |
还是如此的简单,buffer 代表缓冲区的起始地址,size 为缓冲区的大小,in 为写指针,是无符号整型,out 是读指针,也是无符号整型。
从缓冲区读取:
1 | int kfifo_get(struct kfifo *fifo, char *buf, unsigned int len) |
向缓冲区写入的过程是类似的:
1 | int fifo_put(struct kfifo *fifo, char *buf, unsigned int len) |
判断缓冲区空和满都可以通过缓冲区大小得出:
1 | static inline unsigned int kfifo_len(struct kfifo *fifo) |